
OpenTools: Open, Reliable, and Collective Tool-Using AI Agents
Published:
Reading time: 9 minutes
TL;DR
Tool-using LLM agents often fail for two different reasons:
- the agent uses a tool incorrectly (tool-use accuracy), or
- the tool itself is unreliable (intrinsic tool accuracy).
Most prior work focuses on the first issue. In our OpenTools project, we focus on both.
OpenTools introduces a community-driven framework that:
- standardizes tool schemas for plug-and-play use across agent frameworks,
- continuously evaluates intrinsic tool reliability with evolving test suites,
- and provides a public web demo for running tools/agents and contributing failure-driven test cases.
Across multiple agent architectures and benchmarks, better tool quality from OpenTools leads to consistent performance gains over a strong toolbox baseline.
Links
- Paper (arXiv): Open, Reliable, and Collective: A Community-Driven Framework for Tool-Using AI Agents
- Code: github.com/hydang99/opentools
- Web demo: huggingface.co/spaces/opentools/opentools
- Demo video: YouTube walkthrough
Try Live Demo View on GitHub Read Paper
Demo Video
Why OpenTools?
LLM agents are increasingly powerful, but real-world reliability still lags behind expectations. In practice, improving only the agent policy is not enough when tools can drift, break, or silently return unstable outputs.
OpenTools is designed around a simple idea:
Reliable agents require both good tool orchestration and reliable tools.
This perspective motivates a framework that treats intrinsic tool quality as a first-class object to build, evaluate, and maintain over time.
Core Idea: Two Complementary Workflows
The OpenTools framework has two linked workflows:
- Tool Accuracy / Maintenance Loop
- Standardize each tool with a unified interface (description, JSON argument schema, output contract).
- Evaluate tools with test suites using exact/pattern/tolerance/semantic checks.
- Track availability, regression, and reliability metrics over time.
- Let the community contribute new tests and tools to continuously expand coverage.
- Agentic Workflow
- Expose selected tools to an agent (ReAct, OctoTools-style, MultiAgent, or user-defined).
- Execute tool calls with schema validation and structured tracing.
- Return final answers with transparent logs for debugging and reproducibility.
These two workflows are connected: reliability signals from the maintenance loop can inform what tools agents should trust and prioritize.
What the Figure Highlights
The system figure in the paper captures a closed loop:
- top half: community contributions + verifier-driven curation + tool evaluation refresh,
- bottom half: user query -> agent planning -> tool execution -> answer + logs.
In short, OpenTools is not just a toolbox; it is a tool reliability lifecycle.
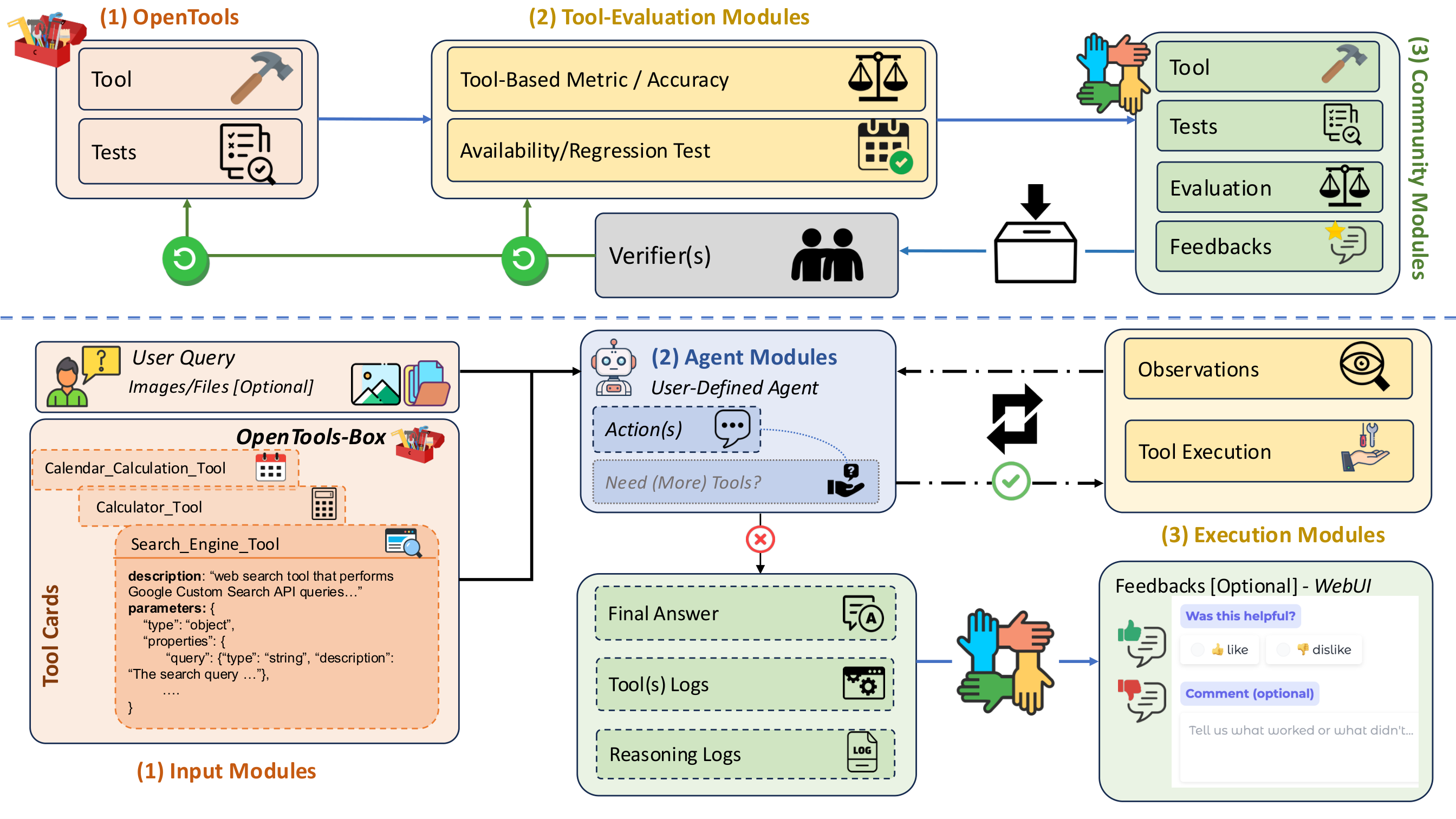
Figure: OpenTools framework overview with the maintenance loop (top) and agentic workflow (bottom).
Main Experimental Takeaway
We compare OpenTools toolbox variants against a strong existing toolbox across diverse tasks (VQA/puzzle, math, science, medical, and agentic tasks) and multiple agent frameworks.
Key outcome:
- Better intrinsic tool quality and broader task-specific tool coverage produce consistent downstream gains.
- Reported relative improvements are in the 6%-22% range across settings.
- Gains are especially strong on harder agentic tasks that require robust external actions.
This reinforces a practical lesson: even strong base LLMs benefit from better tools, and weaker LLMs benefit even more.
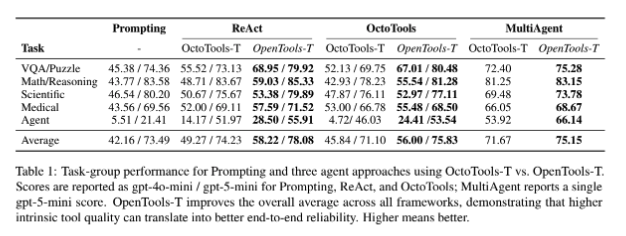
Figure: Table 1 from the OpenTools paper showing consistent gains across frameworks and task groups.
What I Think Matters Most
Three practical implications stand out:
- Separation of concerns is powerful: tool maintenance can evolve independently from agent policy design.
- Community feedback is essential: test suites should be living artifacts that grow from real failures.
- Reproducibility needs infrastructure: standardized interfaces + structured logs + continuous checks make progress measurable.
Looking Ahead
OpenTools is still growing. Important next directions include:
- adding more domain-specific tools (science, medicine, engineering),
- expanding stress tests and regression monitoring for API drift,
- and keeping compatibility with new agent architectures as they emerge.
If you are building or evaluating tool-using AI agents, I would love to hear your feedback and potential collaboration ideas.