Open, Reliable, and Collective: A Community-Driven Framework for Tool-Using AI Agents
Authors: Hy Dang, Quang Dao, Meng Jiang
Venue: Preprint (arXiv 2026)
Paper GitHub Live Demo Blog Post
TL;DR
Tool-using LLM agents often fail for two different reasons: tool-use accuracy (how well an agent invokes a tool) and intrinsic tool accuracy (whether the tool itself is correct and stable). OpenTools focuses on both.
- Standardizes tool schemas for plug-and-play use across agent frameworks.
- Continuously evaluates intrinsic tool reliability with evolving test suites.
- Provides a public web demo where users can run tools/agents and contribute failure-driven tests.
Demo Video
Why OpenTools?
LLM agents are increasingly powerful, but real-world reliability still lags behind expectations. Improving only the agent policy is not enough when tools drift, break, or silently return unstable outputs.
Reliable agents require both good tool orchestration and reliable tools.
Abstract
Tool-integrated LLMs can retrieve, compute, and take real-world actions through external tools, but reliability remains a major bottleneck. OpenTools separates two failure modes: tool-use accuracy (how well agents invoke tools) and intrinsic tool accuracy (whether tools are correct and stable). The framework standardizes tool schemas, supports lightweight wrappers, provides continuous tool evaluation with community-contributed test suites, and exposes a public web demo for running agents/tools and contributing feedback.
Framework Overview
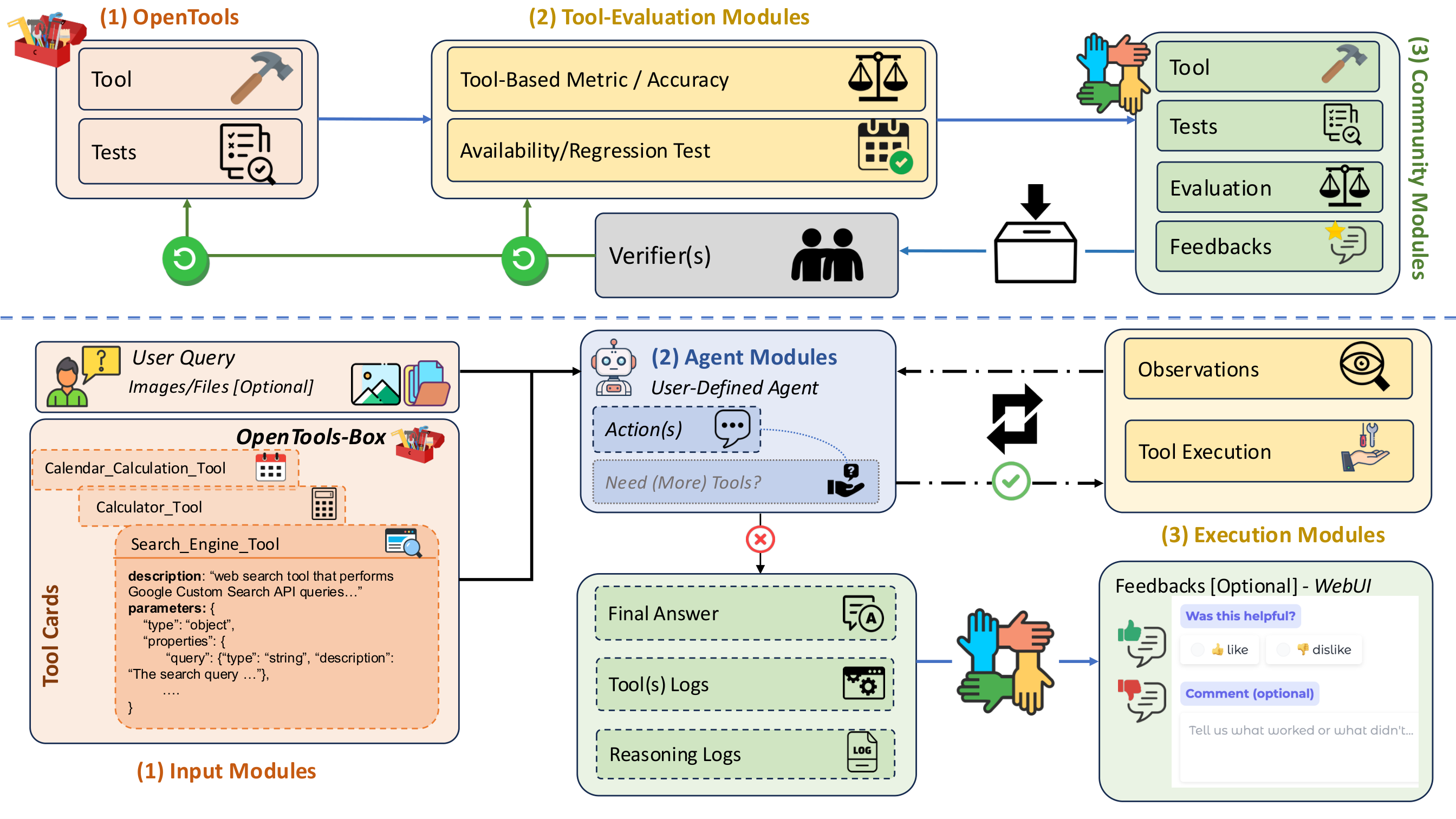
OpenTools connects a maintenance loop (tool evaluation, test updates, reliability tracking) with an agentic execution loop (query, tool calls, logs, final answer).
The top half of the framework emphasizes community contribution and verifier-driven curation for tools and tests, while the bottom half captures end-to-end agent execution with transparent tool/reasoning traces.
Core Idea: Two Complementary Workflows
- Tool Accuracy / Maintenance Loop
- Unifies tool descriptions, JSON argument schemas, and output contracts.
- Runs standardized evaluations (exact/pattern/tolerance/semantic checks).
- Tracks reliability, availability, and regressions over time.
- Continuously expands coverage with community-contributed tests/tools.
- Agentic Workflow
- Supports multiple agent policies (ReAct, OctoTools-style, MultiAgent, and custom).
- Validates tool arguments and records structured traces during execution.
- Produces transparent outputs for reproducibility and debugging.
Main Results
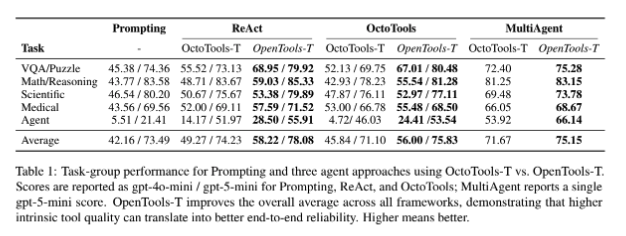
Better intrinsic tool quality and broader tool coverage provide consistent gains across frameworks and task categories.
- OpenTools shows relative gains in the 6%-22% range across settings.
- Improvements are especially strong on harder agentic tasks requiring external actions.
- Even strong base LLMs benefit from better tools; weaker models benefit even more.
What Matters Most
- Separation of concerns: tools and agent policies can evolve independently.
- Community maintenance: test suites should evolve from real observed failures.
- Reproducible infrastructure: standardized interfaces plus structured logs enable reliable iteration.
Looking Ahead
- Expand domain-specific tool coverage in science, medicine, and engineering.
- Strengthen stress tests and regression tracking for API and dependency drift.
- Keep pace with emerging agent architectures using common tool standards.